The Sandbox: the AVSandbox knowledge hub
The Sandbox knowledge hub discusses many of the crucial issues affecting the development, engineering, use and regulation of Autonomous Vehicles.
Scroll to explore

Introduction to Safety Estimation using Intersection Matrix Method
As the world wakes up to the stringent safety tests that will be needed for self-driving cars, the team at Claytex has been working on identifying where they’re most needed, in a method we christened the Intersection Matrix Method. Consider a road network that a self-driving car developer wants to operate in. It could be a whole country, or more realistically, a test city, the cycle lanes of Milton Keynes, or a specific site, like an airport that wants autonomous luggage buggies. The best place for a developer to test if their vehicle is safe is in the most dangerous part of this network. And how do you find it? Let’s consider a scene on the road we all know, where not only do you, the “ego”, negotiate with other traffic, but the traffic negotiates with one another… what we’re describing here is the simple, traffic light-free junction. It’s a rudimentary topology found anywhere from big interchange roundabouts to council-neglected country lanes. When busy, it poses quite a challenge for a pilot-computer to anticipate what will happen, and is difficult to simulate too, because each car needs to make its own logical assessment, and the resulting sequence of car movements can be greatly changed by differences in initial conditions.
Nevertheless. How do you find the most dangerous intersection, and put your self-driving car to a real test with it?
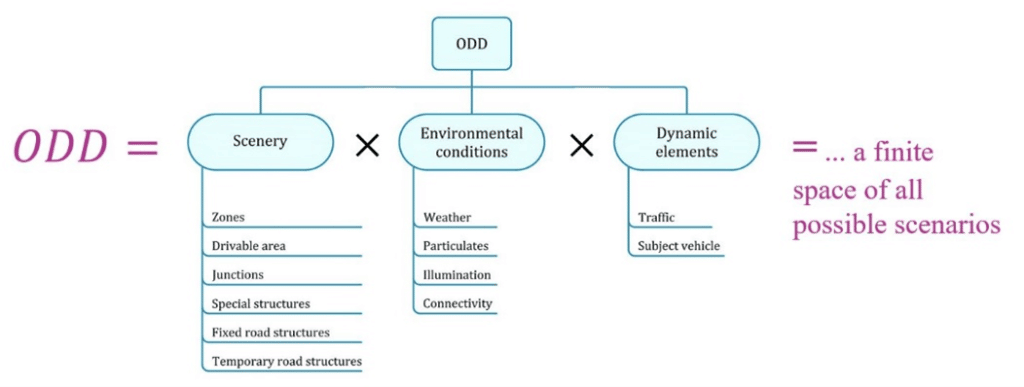
Figure 1: Visual representation of an ODD
To begin this safety estimation, we need to define an intersection and the lanes that go into and out of it. Known as the “Operational Design Domain” and using information that came from an assessment of a road network, it’s meant to capture the typical traffic flow through this intersection and what manoeuvres might cross each others path most often, leading to a higher risk of accidents. As seen in figure 1, an ODD contains all elements that make up a test scenario but we will specifically be focusing on junctions or intersections as they’re also known.

Figure 2: Three way intersection with directional indicators
To begin this method, create a matrix I listing the number of incoming lanes, outgoing lanes and angle of each connected road. Using Figure 2 as an example, we have 3 “roads”, where Road 1 has 1 lane, (incoming traffic only) and Road 2 and 3 have two lanes each – one incoming, one outgoing.

Then, create another matrix known as A which has a width of the number of incoming lanes and a height of the number of outgoing lanes. It shows the possible combinations between them – a car going into the intersection from road 1, and exiting on road 3, would be q1,3 . The value of q1,3 is a boolean – whether such a connection is allowed, or not. For example, in a roundabout, a car could enter from road 2 and exit to road 2 as well. But in most other intersections, this would mean a banned u-turn. So this creates a ‘map’ of the manoeuvres that happen through an intersection.

Figure 5: Matrix Iq
Next, we bring in matrix Iq, which has the flow rates of each lane. This requires studying the intersection, and measuring how much traffic enters and emerges, and from where. This is typically already studied by highway agencies for the country’s busiest intersections, but a self-driving car developer building a proving ground or test network might need to carry this out themselves.

Figure 6: Matrix Aq
Knowing the possible lane connections and the traffic flows in and out of them, some basic matrix operations create Aq, which lists how much traffic makes each manoeuvre. For example, 80% of cars exiting from road 1 might turn to road 2 and the remaining 20% to road 3, giving corresponding values of 0.8 and 0.2

Figure 7: Matrix C
Now that we have defined the intersection and vehicle flow through it, we can start looking at scenarios and events by finding the conflict points within this intersection. Conflict points are points at which two routes through this intersection intersect one another and where a collision between two vehicles are most likely to occur, these can be listed in matrix C.

Figure 8: Calculation of D, Danger, of conflict point
Using this list of all conflict points, we can then calculate the danger for a possible collision occurring at each conflict point using the maximum expected speed and the angle of incidence of a collision to calculate the maximum possible danger associated with this collision point. We can then place these results into matrix D allowing us to see and sort conflict points based on the level of danger at each one. Further, we can show where these conflict points are as shown in figure 9, allowing us to visualise which areas in an intersection are most dangerous and which places should be used in further testing.

Figure 9: Image showing conflict points on 3-way and 4-way intersections
We can now use the estimated danger of each conflict point from matrix D and the vehicle flow rates from matrix Aq to determine how likely a collision is to occur at each conflict point. Repeating this process for all of the intersections in the network, we can tell which is the most dangerous, and which scenarios to generate creating the risk assessment for the ODD. This way, high standards of safety during the development and testing of self-driving vehicles can be upheld.
Written by: Adam Smedley – Software Developer
Please get in touch if you have any questions or have got a topic in mind that you would like us to write about. You can submit your questions / topics via: Tech Blog Questions / Topic Suggestion.

Ultra photorealism in AVSandbox
Thanks to the hard work of rFpro, ultrarealistic light rendering is now available in the AVSandbox toolkit. This is ...

Tackling High Development Costs: How AVSandbox Can Accelerate Your Autonomous Vehicle Deployment
Reducing costs of autonomous vehicle development without compromising AV Safety The development and successful deployment of autonomous vehicles is ...

Determinist Traffic Simulation
Introduction In my previous blog deterministic scenario simulation, I detailed why we define our simulator deterministic and what is ...
